Hey everyone, it is me again. Today, I am back with a very interesting posts on the best CS projects that I have done at Rice University. Pursuing a computer science degree, I was able to take part in some amazing projects and I want to share it to everyone. I cannot share any source code but I can talk about the descriptions of the projects, what technologies and methods I used and what are the results. Note: the list is sorted based on descending order of recency.
COMP 410: Software Engineering Methodology
I have written a detailed post about this amazing class here. Check it out!
COMP 310: Advanced Object-Oriented Programming and Design
Description - Ball World
This class had the most amount of work in the CS curriculum. I learned a lot about object-oriented programming in Java and design techniques can create globe-spanning software systems that are both flexible and scalable. Also, I understand more about how software design patterns are used in multiple programming paradigms and explore highly decoupled systems with dynamically configurable behaviors
This class also had 6 assignments that build up on each other to create a ball world. Sounds quite simple right, but it is actually really complex and scalable. In the project, we make these colorful balls bounce around the screen and they can interact with each other.

- We can define what types of ball it is like Default, Pulse (changing size) or Flashing (changing color)
- Update Strategy: how to update the state of the balls. This could be update in directions, positions, speed, color. Here I am choosing Overlap Criteria, which is 2 balls will change their states after they touch each other
- Paint Strategy: which can change the shape of each ball and repaint the entire interface. Using affine transformation, we can change them to triangles, squares or any images we want and they can still keep the images upright after they bounce off the screen. This is an example of Sonic bouncing around the screens
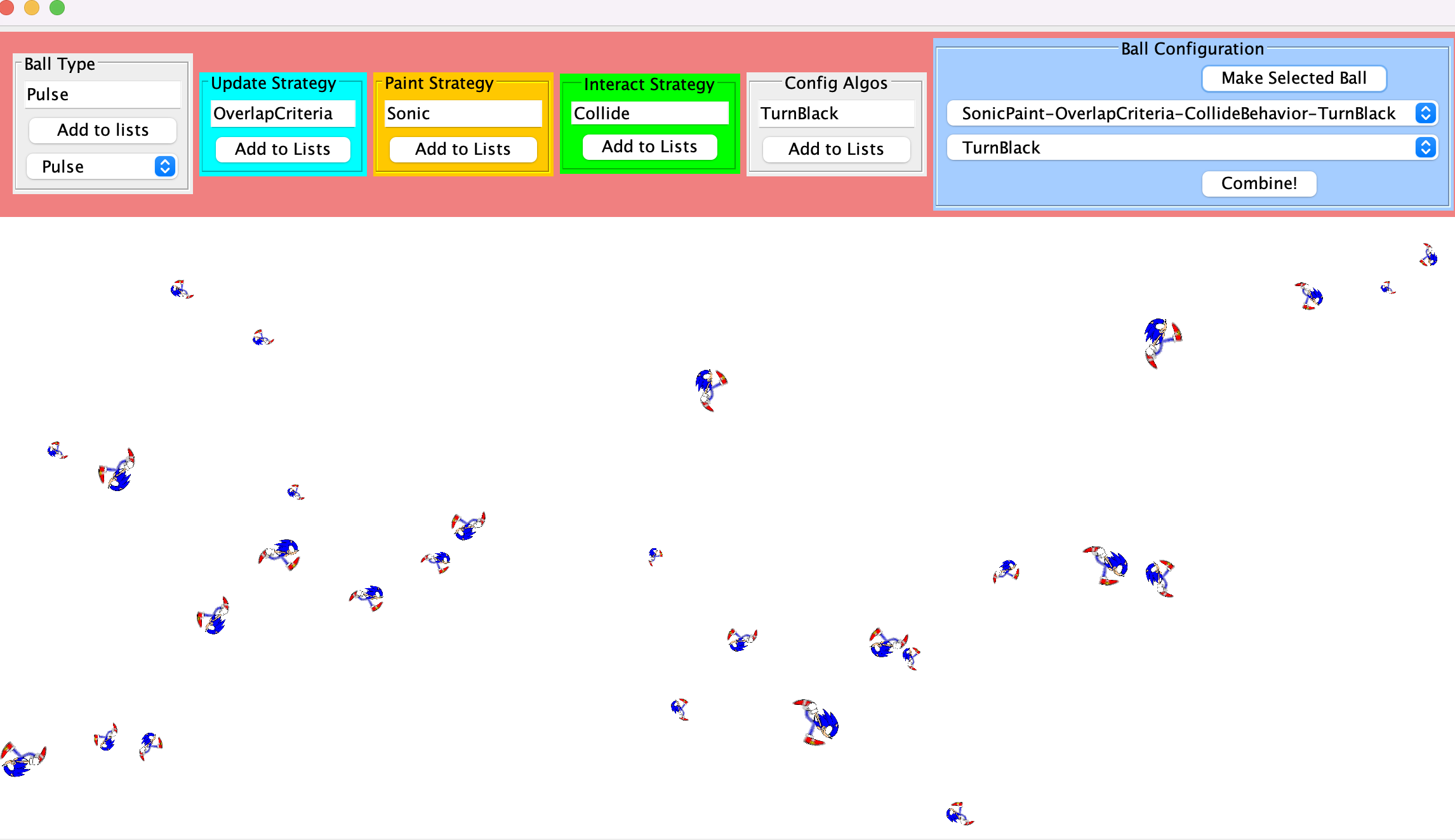
- Interact Strategy: we defined how the balls will interact with each other. In the example, I am setting the balls to have collide strategy which is a kinematic collision and makes them bounce off each other.
- Config Algos: we can dynamically change the strategies and settings for the balls even after we have created them
- Multiple Strategies: we can combine different strategies in a ball. In the example, my balls can have SonicPaint, OverlapCriteria, CollideBehavior and TurnBlack algorithm on toggle.
Technologies/Methods
- Utilized Java OOP, Model-View-Controller design pattern and Visitor design pattern (the algorithms act as visitors and the balls as hosts)
- Created highly-decoupled and scalable system
- Used Eclipse for development and version control and WindowBuilder for building the GUI
Result
- I learned a lot about object-oriented programming in Java, and got used to using Eclipse in developing the design patterns.
- It is super cool that this simple ball world project could show the extend of object-oriented programming and explore so many different design patterns.
COMP 646: Deep Learning for Vision and Language
Description - Movie Genre Classification from plots and images
Just like the name, this graduate class is focused on deep learning for vision and language. What a time to be taking this class when ChatGPT is taking schools by storm. This is the class that made me really interested in LLM and processing images in vision models. After the class, I acquired the skills to build machine learning and deep learning models that can reason about images and text for generating image descriptions, visual question answering, image retrieval, and other tasks involving both text and images. On the technical side we will leverage models such as recurrent neural networks (RNNs), convolutional neural networks (CNNs), and transformer networks (e.g. BERT, GPT-3, ViTs)
My favorite project in the class is performing Movie Genre Classification from plots and images of movies posters. I used the MMIMDB dataset (https://github.com/johnarevalo/gmu-mmimdb). This dataset contains data corresponding to ~26,000 movies along with their plots (text) and their movie posters (images), and other information such as ratings and genres (categories). Each movie can be labeled with 27 categories of movies
Technologies/Methods
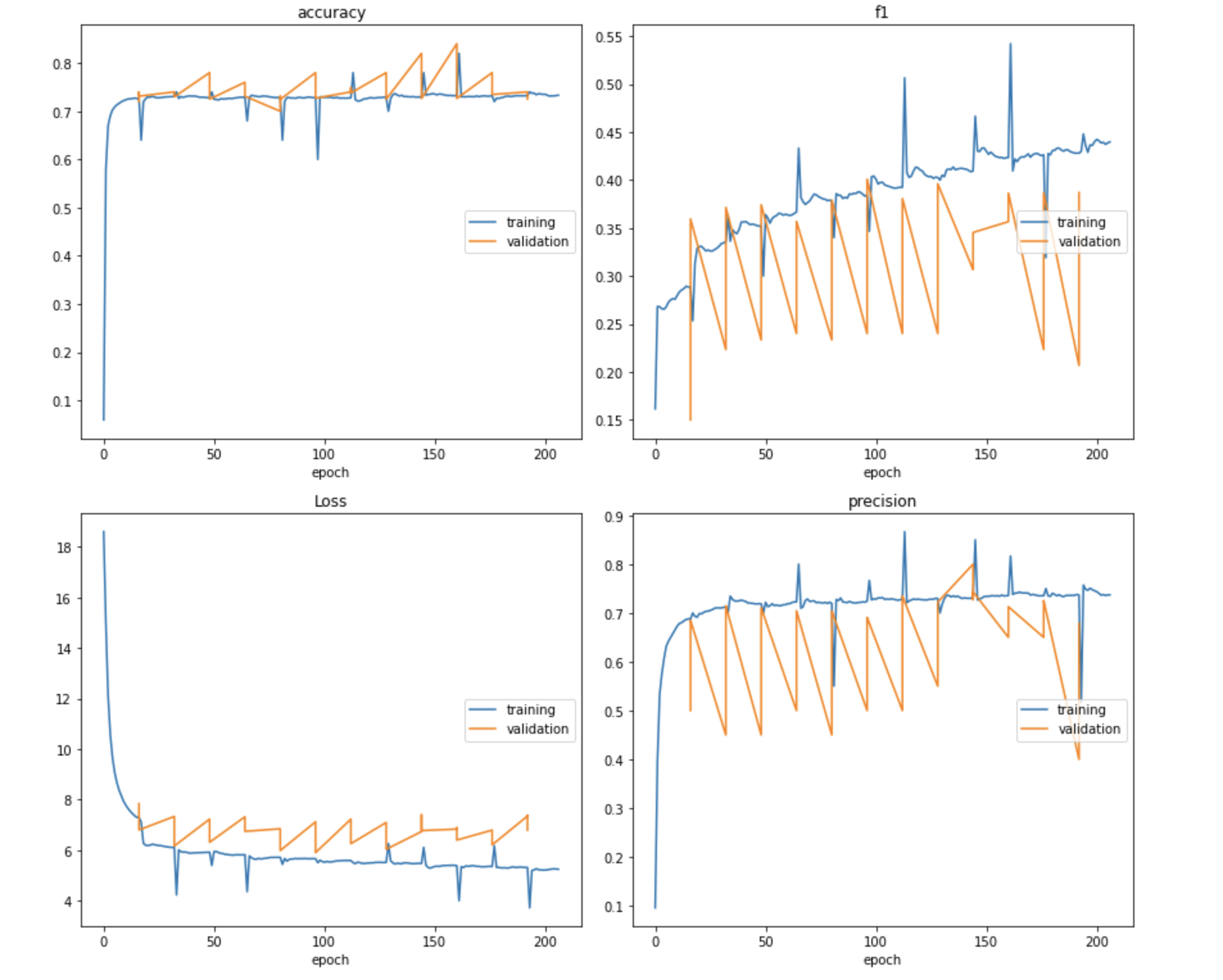
- Implemented the predefined BERT Transformer Model to predict the top 5 classification predictions using the nn.BCEWithLogitsLoss and the sigmoid function
- Finetuned ResNet50 with weight “ResNet50_Weights.IMAGENET1K_V2” on the dataset to predict the genres based on the images
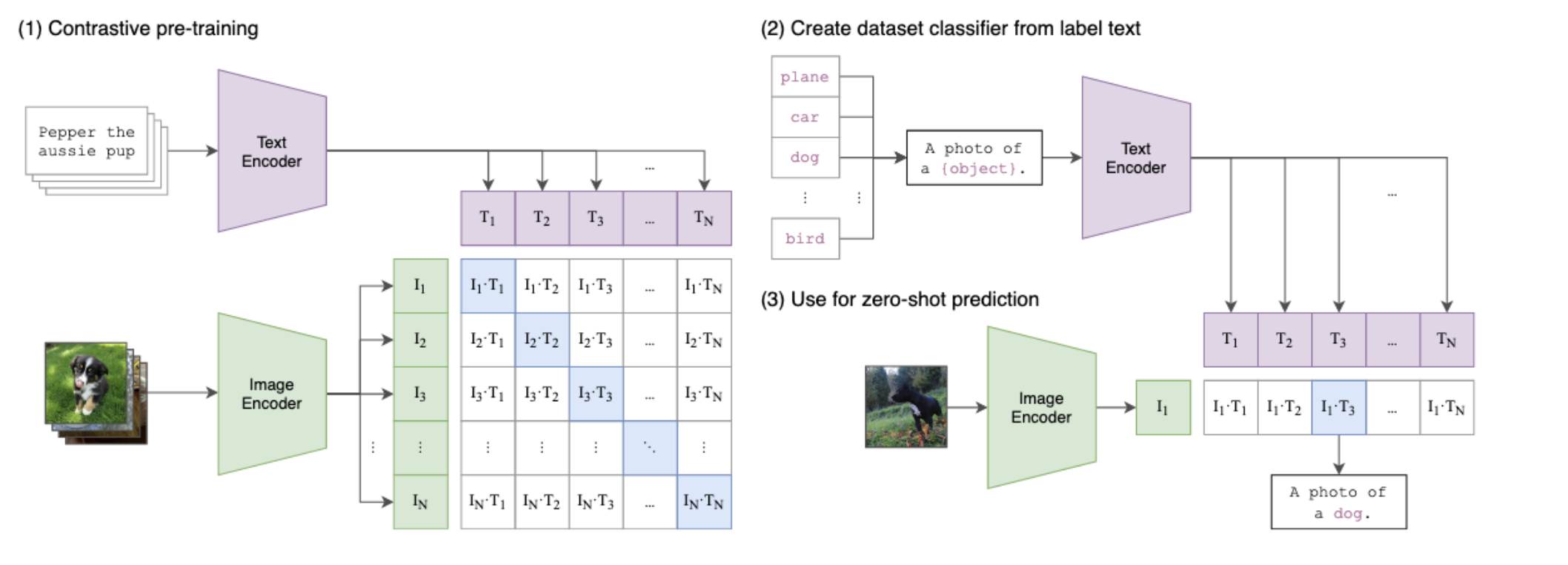
- Performed Zero-shot Text Classification with FLAN-T5 with an engineered prompt to predict the genres based on examples
- Performed Zero-shot Image Classification with CLIP using the ViT-B/32 model.
Result
- The CLIP model seems to produce the highest accuracy in predicting the genres
- Learned how to write a deep learning model from preparing and cleaning the datasets, defining data loaders, and writing training loops for fine tuning the model to showing visualizations and predicting the results.
- Worked on a Final Project Paper on Explorations on Detection and Captioning with Named Identities.

COMP 421: Operating Systems and Concurrent Programming
Description - Operating System Kernel
This for me is certainly the hardest and most challenging class in the Rice CS curriculum. It is the next class after COMP 321 where we dive deeper into operating systems.
The course focuses on the control and utilization of processor, memory, storage, and network resources. The concepts in this course include operating system structure, process management and scheduling, interprocess communication, synchronization of concurrent processes, deadlock, main and secondary storage management, virtual memory, file systems, protection and security, and some introduction to networking
In particular, there are 3 big projects in the course that are:
-
Project 1: you will implement a terminal device driver using a Mesa-style monitor for synchronization of interrupts and concurrent driver requests from different user threads that share an address space
-
Project 2: (the most dreaded project in the Rice CS Curriculum) you will implement an operating system kernel for the Yalnix operating system. The Yalnix operating system is similar in many ways to the Unix operating system, with multiple processes, each having their own virtual address space. The system also supports a system console and a set of terminals on which users can do input and output
-
Project 3: you will implement a simple file system for the Yalnix operating system kernel (project 2) as a server process. The YFS file system will support multiple users, with a tree-structured directory, and will be similar in functionality and disk layout to the “classical” Unix file system. Client processes using the file system send individual file system requests as messages to the file server process. The server handles each request, sends a reply message back to the client process at completion, and then waits for another request to arrive at the server
The most challenging but rewarding project for me is the Operating System Kernel. In the project, I get to work on most of the basic features of a Unix operating system including:
- Interrupts, Exceptions, and Traps
- Yalnix Kernel calls like Fork, Exec, Exit, Wait, Delay, Read Terminals and Write Terminals
- Memory Management with Page Tables and virtual memory
- Context switching between different processes

Technologies/Methods
- Developed the Operating System Kernel using C. Write detailed test programs for the kernel covering all the functions of the kernel
- Used a computer system hardware known as the Rice Computer Systems RCS 421
- Utilized Linux command lines to run the programs and processes
Result
- Created a working operating system kernel from scratch using C
- Run a lot of test programs and call different functions on the Operating System Kernels
- Know more about programming in Linux and SSH Remote Develoment

COMP 341: Practical Machine Learning
Description - Deep Learning Classifier of clothes
This was another machine learning class that I took at Rice University. It covers how to apply ML algorithms to real world problems. I learned about data augmentation, bias detection, feature engineering, efficient tuning and training, model interpretation, and data storytelling
My favorite project in the class was building a deep learning classifier to identify items of clothing from black and white images from the dataset FashionMNIST. Basically, there are 10 categories of clothes and we need to build a classifier to do a single classification (predict 1 category) based on an image.
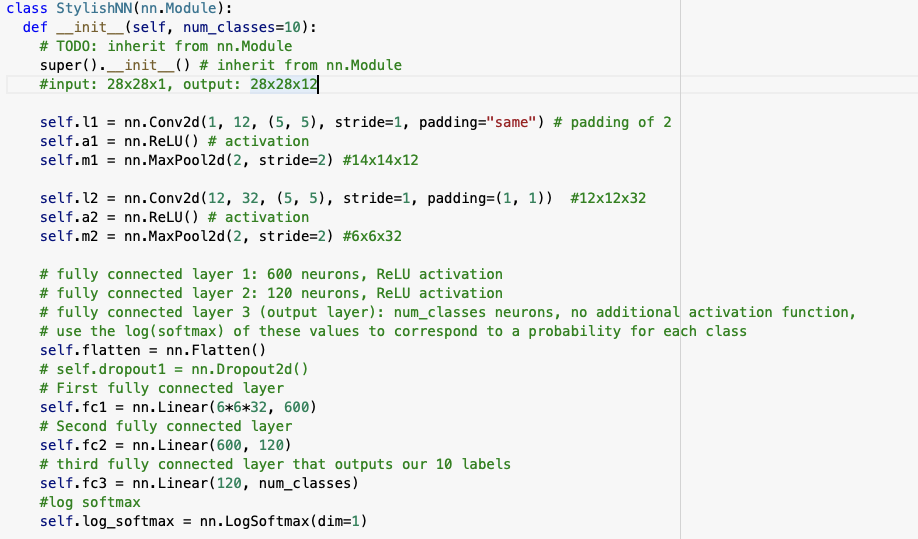
I built a deep learning CNN model using 2 convolutional layers and 3 fully connected linear layers and with a log_softmax prediction for each class to determine a single classification for the clothes image.
Technologies/Methods
- I used Google Colab for most of my work. I used the GPU from Google Colab to train the deep learning model
- I used Python, PyTorch, and NumPy to do the project
- I built a CNN model with 2 convolutional layers: first convolution layer has 12 filters each filter is 5x5, taking strides of 1, and padded to maintain the original image size and the second convolution layer has 32 filters of 5x5, taking strides of 1, padding 1.
- After each convolutional layer, I also apply a ReLU activation layer and a max pool 2d to maximize the accuracy of predicting the image
- I used 3 fully connected layers: 600 neurons, ReLU activation + 120 neurons, ReLU activation + output layer
Result:
- At the end, I achieve about 55% maximum accuracy after 60 epochs, which is pretty good for a “hand-made” classifier.
- I also tried fine-tuning using ResNet50 and the result was 92% after just 3 epoch. Crazy right?

COMP 322: Intro to Parallel Computing
Description - Parallel implementation of Smith-Waterman Algorithm
This was the first class at Rice University that taught us parallel computing in computer science. We get introduced to concepts such as lazy computations, map reduce with java streams, futures, async/await, data-driven futures, computation graphs, Parallel Speedup, Amdahl’s Law. There are also important topics on synchronization such as thread, lock in operating system.
As a person who loves solving algorithm, I am very intrigued by an assignment to parallelize a famous algorithm. We know that a number of alignments exist for a given pair of sequences; therefore, we define a scoring scheme that gives higher scores to “better” alignments. In this project, we get introduced with Smith-Waterman algorithm, which is a dynamic programming algorithm that finds the optimal scoring for Pairwise Sequence Alignment

Here is the dynamic programming formula for the optimal scoring
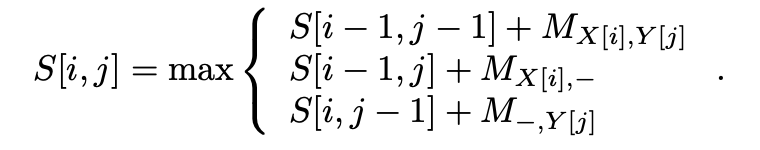
Technologies/Methods
- We used Java and a custom library called Habanero Java that contains important synchronization functions such as futures, async/await, data-driven futures.
- We used JUnit to create exhaustive test cases for all of our functions and Intellij as the main IDE
- We divided the rectangle into smaller chunks (squares of size 120, depending on the number of cores of each machine) and used data-driven futures to parallelize the computations of each of the chunk
- Run all the chunks of size 120 that I created concurrently using for-all construct and inside each chunk I will calculate the values of each cell sequentially. Using finish/async, when I calculate chunk m[i][j], I still need to wait for chunks m[i - 1][j], m[i][j - 1] and m[i - 1][j - 1] to complete to get the needed values for calculating the cells
- We used a system called NOTS (from Rice University) that is a batch scheduled HPC/HTC cluster running on the Rice Big Research Data (BiRD) cloud infrastructure to run the parallel scoring program and check the scores
Results:
- The program is correct and data-race free.
- The parallel program ran 13.5 times faster than the sequential version of the algorithm. How cool is that!

COMP 321: Introduction to Operating Systems
Description - Multithreaded HTTP Web proxy
This was the first class on computer system and operating systems at Rice University. We learned a lot of low level programming in the class including C and Assembly. The major topics of this course include linking, exceptions, memory allocation and management, networking, and concurrency. These topics are important in all computer systems and will prepare me for learning compilers, operating systems, computer architecture, and networking
The most interesting project that I did in the class was a multithreaded HTTP Web proxy. A web proxy is a program that acts as a middleman between a web browser and an end server. I created a proxy so that it uses threads to deal with multiple clients concurrently, supports the HTTP GET and CONNECT methods and supports HTTP/1.0 and HTTP/1.1 requests
This is an example of a GET request to http://neverssl.com/. It will return all the text/HTML contents from the website.
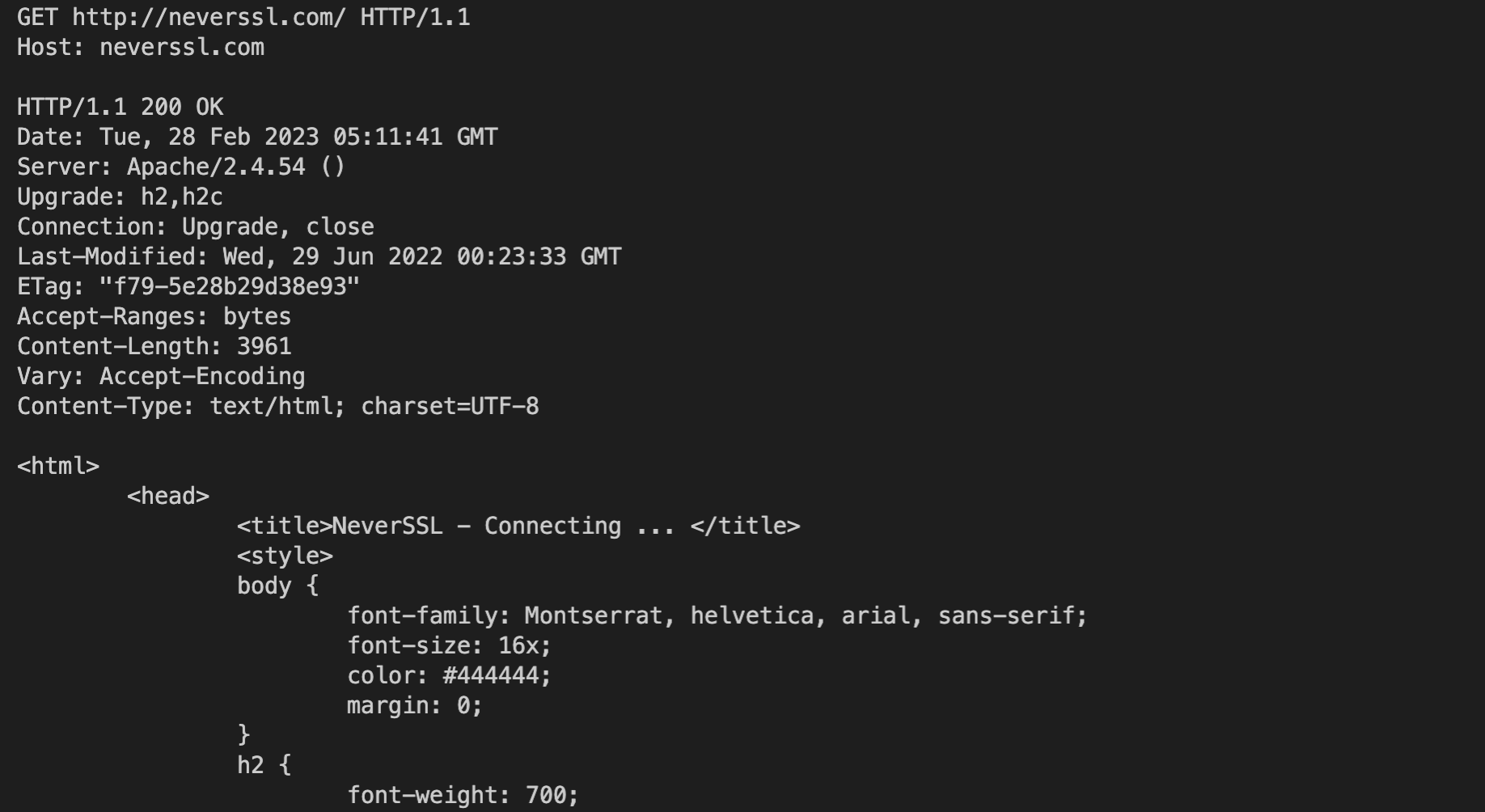
Technologies/Methods
- I used C and different libraries in C to write all the project
- I have a mutex lock (mutex) to handle concurrency between threads and we also store all the requests in an array of buffers of requests.
- Some important libraries and functions used include interrupt handler using signals, using Pthread to manage concurrency and the critical section, and malloc, realloc for dynamic memory allocation. I also used rio_readline and rio_write to read and write data in the proxy.
- I used a system called CLEAR (from Rice University) that a robust and dynamic Linux cluster to run my proxy
Results:
- We were able to handle almost 20 concurrent client connections calling GET requests of different pages. Still a small number but thats incredible!
- It could also read pages with images, and really long websites as well
COMP 330: Tools & Models - Data Science
Description - Text Documents Classification
This was the first machine learning/data science class that I took at Rice University. The course focused both on the software tools used by practitioners of modern data science, and the mathematical and statistical models that are employed in conjunction with such software tools. We learned the basics of relational database systems, modern systems for distributed computing based on MapReduce and standard supervised and unsupervised models for data analysis and pattern discovery.
The projects in this class helped me understand highly advanced tools and models for data science and all the assignments have real-life application. However, the best project is implementing a regularized, logistic regression to classify text documents. We are given 170,000 text documents and we need to classify whether a text document is an Australian court case.

Technologies/Methods
- Convert each of the documents in the training set to a TF-IDF vector. Then used a gradient descent algorithm to learn a logistic regression model that can classify each vector → producing words with the largest regression coefficients, most strongly related with an Australian court case
- Implemented the models in NumPy and Python on top of Spark.
- Used Amazon AWS deep learning instances (G instances) to get enough GPU to train large datasets
Results:
- At the end, I achieved a F1-score on my predictions of 0.85. This is a pretty good number for the model.
- This project taught me a lot about how to use Spark to dealing with Big Data, implementing machine learning algorithms such as LLH or Gradient Descent
COMP 215: Introduction to Program Design
Description - Test case Generator
This was the first class on program design and object-oriented programming using Java. I learned about basic principles of software design, including: encapsulation, abstraction, test-driven development, and functional and object-oriented programming
The interesting thing about the class is the assignments in the class combine together to make a large project that is significant and a real-world application. I implemented an automated tool for generating test cases for a Python function
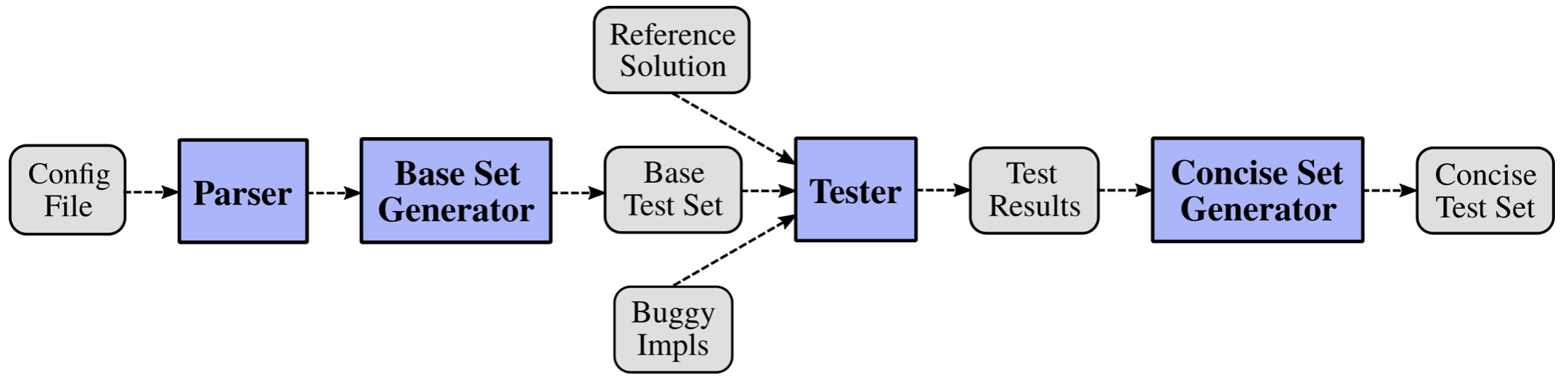
There are four components to the system that I was able to implement: parser (processes the config file and builds a template for generating test cases), base set generator (creates a large base test set for the function under test), tester (runs each test in the base test set on each buggy implementation and outputs the results and concise set generator (utilize the test results to select the minimal subset of the base test)
Technologies/Methods
- I utilized Java OOP knowledge such as encapsulation and abstraction to create classes to represent simple Python objects such as bool, string, int, float and compound Python objects such as list, set, tuple, dictionary.
- We used JUnit in Intellij to create exhaustive test cases for all of our functions
- It was really interesting that I get to use recursive functions and greedy algorithms to construct the concise set and base set of test cases.
- Also, I wrote a parser for JSON files that contain strings that are written following a grammar, expressed in Backus-Naur form
Result
- I learned a lot about object-oriented programming in Java, and got used to using IntelliJ.
- It is super cool that I know how to construct Python objects in Java and created an end-to-end test cases generator for any python functions.
COMP 182: Algorithmic Thinking
Description - Part of speech tagging
This was definitely one of the most challenging classes that a CS student has to take. I used to spend about 20 hours a week for this single course. This course introduces discrete mathematics and algorithmic thinking as a discipline for reasoning about systems.
The most interesting project that I did in the class was Part of Speech Tagging (POS). This is the process of assigning a part of speech or other syntactic class marker to each word in a corpus. The input to a tagging algorithm is a string of words and a set of tags (‘adjective,’ ‘noun,’ ‘adverb,’). The output is a single best tag for each word. We have 2 models bigram (The probability of a tag appearing is dependent only on the previous tag in the sequence) and trigram (The probability of a tag appearing is dependent only on the previous 2 tags in the sequence)
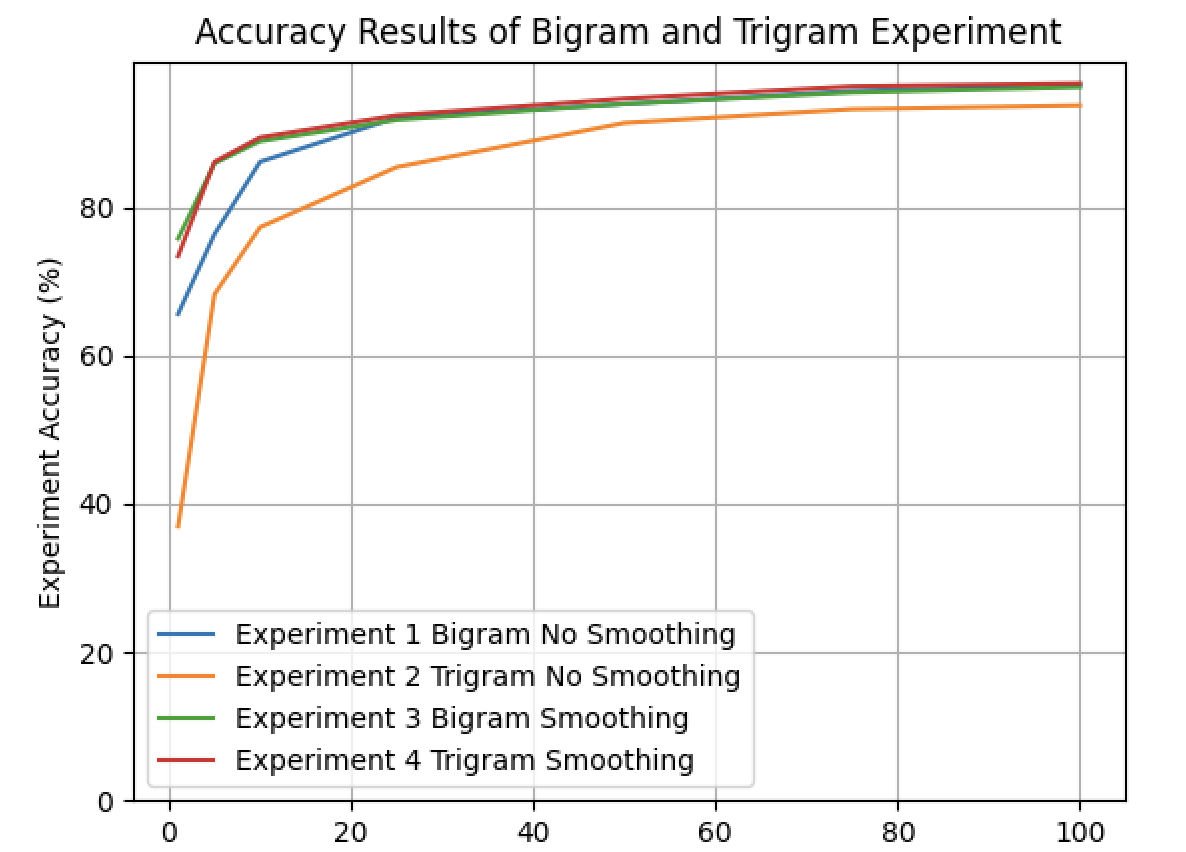
Technologies/Methods
- I used HMMs (Hidden Markov Models) to do POS tagging (a special case of Bayesian Inference)
- In both the bigram and trigram models, the emission matrix is a two-dimensional dictionary where the first key is the tag and the second key is the word
- I used Viterbi algorithm (dynamic programming) to calculate the transitions probabilities between the states of the HMM.
- We represent the HMM and implemented the algorithm using Python in PyCharm
Result
- In general, as we increase the training data percentage, we have a higher accuracy in both bigram and trigram models. Bigram and Trigram models with smoothing achieve high accuracy both at the beginning and the end
- I was able to implement a highly complex algorithms and analyze its results in just 2 weeks. I learned a lot about how to use different data structures in Python and how to approach implementing a complicated algorithms
COMP 140: Computational Thinking
Description - Map Search
This was a first class that any CS students in Rice University will take. This course provides an introduction to computational problem solving designed to give an overview of computer science using real-world problems across a broad range of disciplines.
The most notable project that I was able to do is Map Search. In the assignment, we implemented graph search algorithms to search a street map to find a route from a start point to an end point. We explore 3 different search algorithms and compare them with Google Maps
- Breadth-First Search
- Depth-First Search both iterative and recursive
- A* Search

Technologies/Methods
- I implemented different graph search algorithms including DFS, BFS and A* search.
- We used Python for all of the project and we are given a GUI to show the map.
Results
- Eventually, from this example map, we are finding the route from Duncan Hall (CS building) to a place outside of Rice University. The BFS algorithm gave us the best result compared to the other 2 methods. What a cool project!
If you like this blog or find it useful for you, you are welcome to leave a comment. You are also welcome to share this blog, so that more people can participate in it. If the images used in the blog infringe your copyright, please contact the author to delete them. Thank you so much!